
Understanding nvision Training Times: Data, Hardware, and Engineering Trade-offs
One of the most common questions around AI-based surrogate modelling is simple:
How long will model training take?
The honest answer is that there is no universal number. Training duration depends on many factors, including dataset size, number of outputs, hardware configuration, and model complexity. However, understanding how these factors influence training behaviour is often more useful than trying to estimate absolute durations.
More data, longer training. Usually for a good reason.
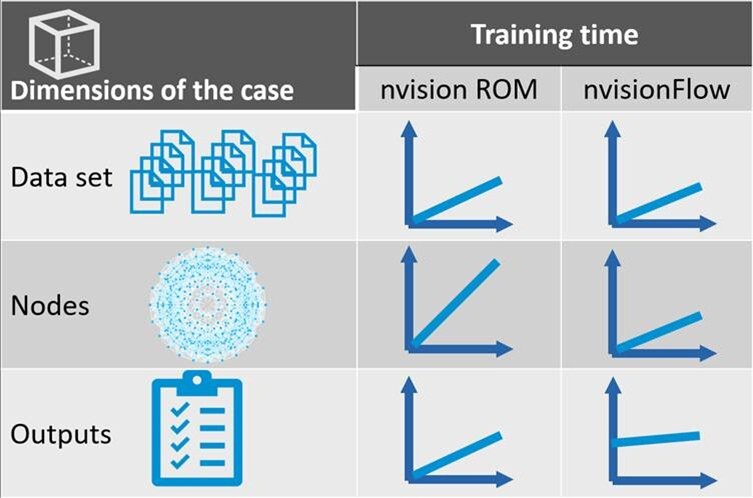
Both nvision ROM for parametric cases and nvisionFlow for non-parametric cases scale in a relatively straightforward way with respect to dataset size. Increasing the number of training samples increases training time almost linearly.
At first glance, this may encourage users to keep training sets intentionally small. If the bounds of the design space are covered, why wait longer?
In practice, this approach rarely works well unless the problem itself is almost perfectly linear. Richer datasets generally lead to more robust and accurate models, especially for nonlinear engineering behaviour. In surrogate modelling, waiting a little longer for training is often a worthwhile investment.
Large simulations require smarter strategies
Modern simulation workflows easily reach millions of nodes, which naturally raises concerns about practical training limits. Yes, the number of nodes in each simulation impacts training duration. For nvision ROM, the relationship is close to linear. nvisionFlow is also affected by node count, although the scaling is typically less steep.
For nvision ROM, partitioning can significantly improve both training efficiency and predictive quality. By splitting the simulation domain into smaller regions, the complexity handled by each submodel is reduced. Although the total number of nodes remains the same, each subproblem becomes easier to learn, resulting in shorter training times and often better local accuracy.
nvisionFlow approaches the problem differently through subsampling. Instead of learning from the full dataset at every epoch, the model trains on a defined percentage of the available data. This keeps training manageable even for very large non-parametric datasets.
These two approaches address complexity differently:
- partitioning reduces spatial problem complexity
- subsampling reduces the amount of data processed during each training iteration
Multiple outputs also matter
Training time is also influenced by the number of outputs.
This effect is particularly visible with nvision ROM. nvisionFlow is also affected, although generally to a lesser extent. Even so, training a single model with multiple outputs remains significantly more efficient than managing separate models for each quantity of interest.
Hardware matters, especially for nvisionFlow
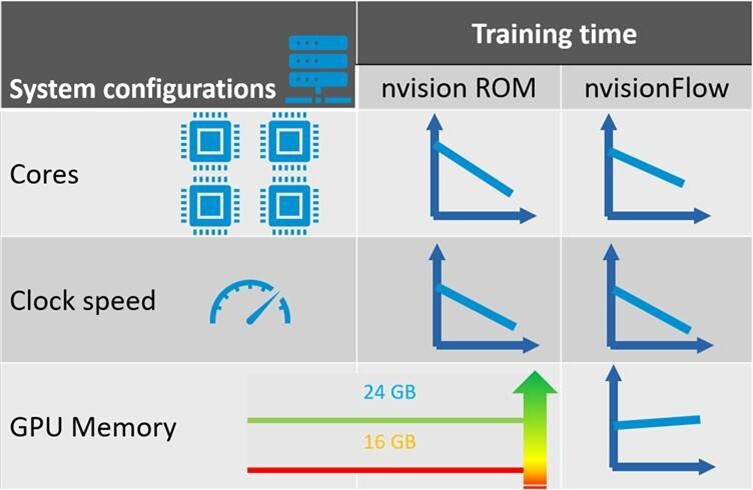
Hardware configuration plays a major role in training performance.
nvisionFlow requires a CUDA-compatible GPU for practical usage. While CPU execution is technically possible, training times become prohibitively long for demanding transient cases. For highly complex models, CPU execution may even be restricted to avoid saturating the system.
CPU performance still matters for both nvision ROM and nvisionFlow. Higher clock speeds and more cores both contribute to shorter training times.
GPU memory, however, is often misunderstood. More GPU memory does not directly make training faster. Instead, it enables the use of larger and more demanding model configurations. In practice, users with more GPU memory often choose richer hyperparameter settings, which can actually increase total training time while improving predictive capability.
For nvisionFlow, 16 GB of GPU memory is considered the minimum practical requirement, while 24 GB or more enables significantly more flexibility for demanding engineering problems.
There is no single formula
Training time in engineering AI is not governed by a single parameter. Data size, node count, outputs, hardware, and model strategy all interact with each other.
The important point is not only how fast a model trains, but how effectively computational resources are transformed into predictive engineering knowledge.
Other posts
-
Simulation insights in a click: scaling expertise beyond specialists
Jul 17, 2026
-
Bringing SimApp Creation Inside the id8 Platform
Jun 04, 2026
-
What’s New in nvision 2026.1
May 19, 2026
-
Why Cost Optimization Should Start at the Design Stage
Apr 23, 2026
-
How Optimus Powers Trustworthy Data for the Next Generation of Design
Feb 25, 2026
©2026 Noesis Solutions • Use of this website is subject to our legal disclaimer
Cookie policy • Cookie Settings • Privacy Notice • Design & Development by Zenjoy